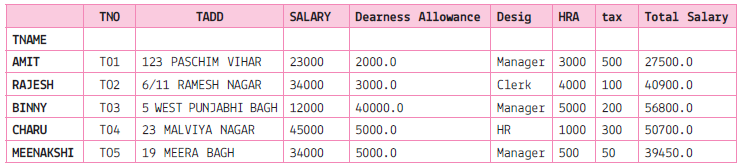
| City | Hospitals | Schools | |
| 0 | Delhi | 189 | 7916 |
| 1 | Mumbai | 208 | 8508 |
| 2 | Kolkata | 149 | 7226 |
| 3 | Chennai | 157 | 7617 |
(a) Choose the right statement to get the given output:

(i) Df1.mean()
(ii) Df1.mean(axis=1)
(iii) Df1.average()
(iv) Df1.median()
(b) Write the command to get the given output:
| City | Hospitals | Schools | |
| 3 | Chennai | 157 | 7617 |
| 0 | Delhi | 189 | 7916 |
| 2 | Kolkata | 149 | 7226 |
| 1 | Mumbai | 208 | 8508 |
(i) Df1.sort(by=‘City’)
(ii) Df1.sort_values(‘City’)
(iii) Df1.sort_values(by=‘City’)
(iv) Df1.sort_values(by==‘City’)
(c) Choose the right statement to get given output:
| Hospitals | Schools | |
| count | 4,000000 | 4,000000 |
| mean | 175.750000 | 7816.750000 |
| std | 27.584718 | 540.543785 |
| min | 149.000000 | 7226.000000 |
| 25% | 155.000000 | 7519.250000 |
| 50% | 173.000000 | 7766.500000 |
| 75% | 193.000000 | 8064.000000 |
| max | 208.000000 | 8508.000000 |
(i) Df1.desc()
(ii) Df1.statistics()
(iii) Df1.desctibe()
(iv) Df1.showall()
(d) Chose the right function to fill in given statement to make the city as index value:
Df1._________________(‘City’,inplace=True)
(i) Df1.set_index(‘City’,inplace=True)
(ii) Df1.index('City',inplace=True)
(iii) Df1.new_index(‘City ‘,inplace=True)
(iv) Df1.reset_index(‘City’,inplace=True)
(e) Which Pandas command is used to rename the columns & index name of the above dataframe
(i) Df1.renamecolumns()
(ii) Df1.Rename()
(iii) Df1.rename()
(iv) Df1.indexrename()
(b) (iii) Df1.sort_values(by=‘City’)
(c) (iii) Df1.describe()
(d) (i) Df1.set_index(‘City’,inplace=True)
(e) (iii) Df1.rename()